|
|
|
|
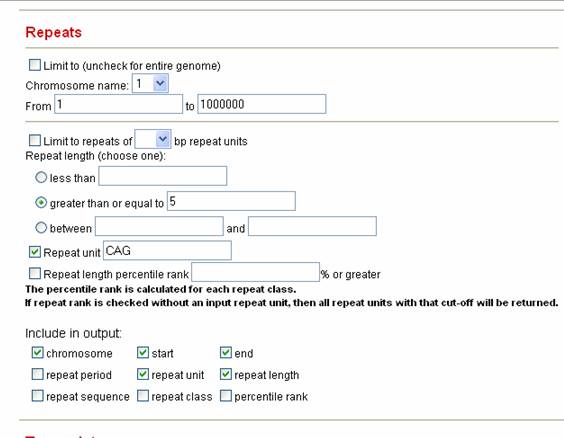
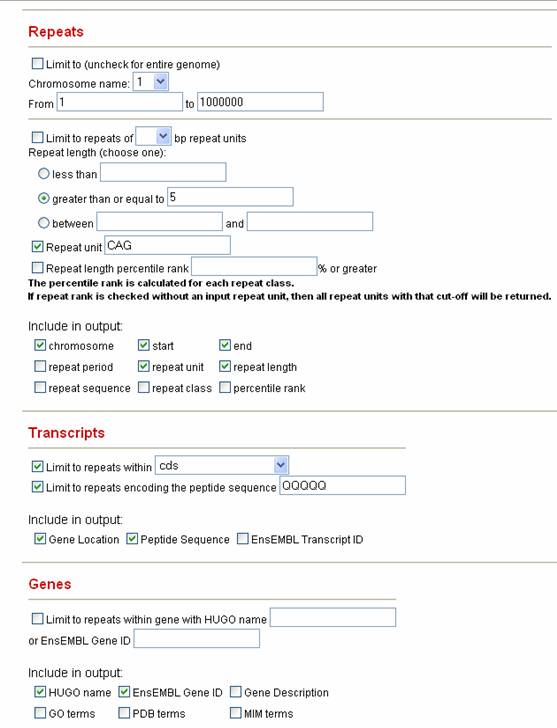
Table of Contents 1.2 The satellog tutorial The satellog tutorial provides step-by-step instructions, along with screenshots, about how to generate queries of interest to biologists. In each scenario we provide an example problem and show how to go about getting an answer from the web-based version of satellog. Power users desiring more complex queries should download satellog from Downloads and run a local instance. 1.2.1 Show me all the CAG repeats in the human genome that are repeated more than 5 times and are located within coding sequences. First we specify the repeats in which we are interested with the repeats table.
1) Uncheck the Limit to box because we are interested in the genome-wide distribution of CAG repeats. 2) Click the radio button greater than or equal to and input 5 because we are interested in all CAG repeats that are repeated 5 or more times. 3) Leave Repeat Unit on its default value, CAG 4) Select the Output variables of interest Secondly, we specify other transcripts and gene information that is of interest to us about these CAG repeats.
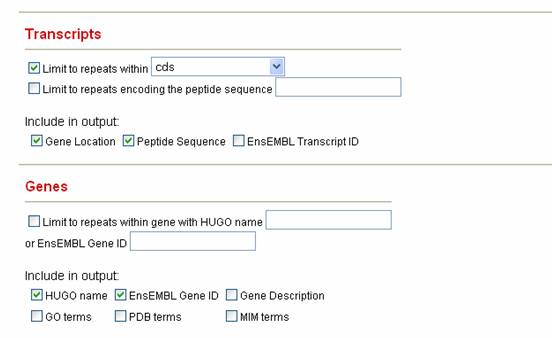
5) Under transcripts, we check the Limit to repeats within box and select cds since we are only interested in coding CAG repeats. 6) Since we would like to see in the output both the location of the repeat within genes and the encoded peptide, we check Gene Location and Peptide Sequence. 7) Usually a given repeat is more interesting if within certain genes. a. Under Genes, we can get information about which gene our repeat is in by checking selecting HUGO name which returns the HUGO (HUman Genome Organization) name of the gene each CAG repeat is in b. Next we check EnsEMBL Gene ID in case we wish to do more bioinformatics with this gene with the EnsEMBL Genome Browser (www.ensembl.org). 8) By default Satellog produces HTML output to screen. If you want another output format, or want the results e-mailed to you, select your preference prior to submitting your query.
9) Click Submit.
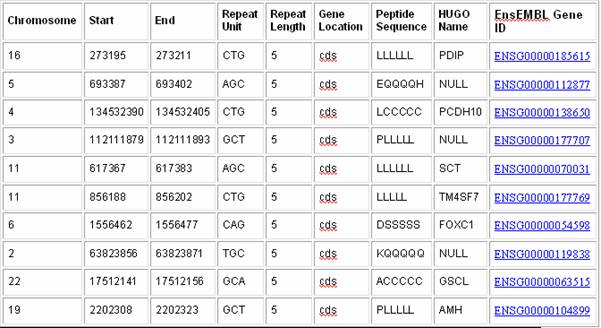
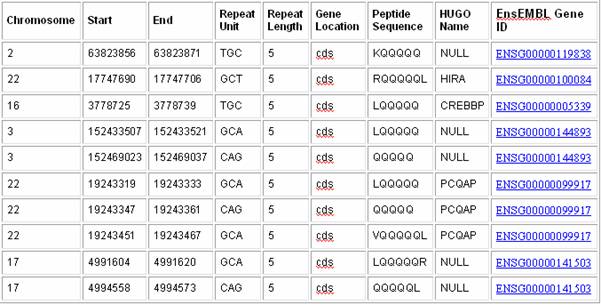
Sample Satellog Output This query gives all the CAG repeat co-ordinates that are within coding sequences, along with the peptide sequence they encode, the HUGO name of the gene they are within and their EnsEMBL Gene ID (output truncated for example).
You may be wondering why CTG, AGC, GCT, TGC, and GCA repeats came up when we asked for CAG repeats. There is a reason for this. A repeat can be represented in a number of ways in double-stranded DNA. Repeats are detected by their first tandemly repeated unit, therefore, CAGCAGCAG, AGCAGCAGC, and GCAGCAGCA are detected as repeats of CAG, AGC, and GCA respectively. Furthermore, the reference human genome sequence is only presented as the positive strand. Repeats of GTC, TCG, and CGT on the positive strand represent 5->3 CAG, AGC and GCA repeats respectively on the negative strand. Therefore, to identify all CAG/CTG repeats in the human genome its necessary to detect all CAG, AGC, GCA, GTC, TCG, and CGT repeats on the positive strand. To account for this, whenever we ask for a certain repeat type, all theoretical variations of the repeat unit are returned by Satellog. 1.2.2 Show me all the CAG repeats in the human genome that are repeated more than 5 times and are located within coding sequences and encode at least five glutamines. Recently, expanding CAG repeats that encode glutamine tracts have been implicated in a number of neurodegenerative disorders. It is possible to select only those repeats that encode glutamine tracts with Satellog.
1) Repeat the steps in 1.2.1. 2) However, under Transcripts also select Limit to repeats within and input QQQQQ.This will return only the subset of repeats that encode five or more glutamines.Of course, this query can be run with any other plausible repeat unit and peptide combination. 3) Click Submit. Sample Satellog Output This query gives all the CAG repeat co-ordinates that are within coding sequences, along with the peptide sequence they encode, the HUGO name of the gene they are within and their EnsEMBL Gene ID (output truncated for example). However, in this example, only those repeats encoding at least five glutamines are output.
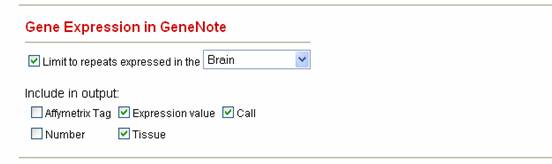
1.2.3 Show me all the CAG repeats in the human genome that are repeated more than 5 times and are located within coding sequences, encode at least five glutamines and are expressed in the Brain. Often repeats are only of interest if they are within genes that are expressed in certain tissues.All genes in Satellog are cross-referenced to the GeneNote (Gene Normal Tissue Expression) database. The GeneNote database is a collection of AffyMetrix microarray experiments run with twelve normal human tissues. With GeneNote, it is possible to see if repeats are associated with a gene that is expressed in a tissue of interest. 1) Repeat the steps in 1.2.2
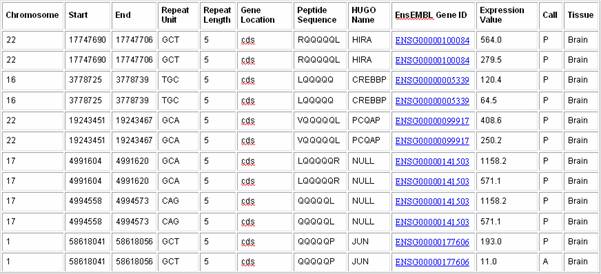
2) Under Gene Expression in GeneNote, check Limit to repeats expressed in the and select Brain from the drop-down box. 3) Next select the following variables: a. Expression Value refers to the absolute intensity value on the chip, can give an indication of significant tag expression b. Call reported by the AffyMetrix analysis software, P, M, and A refer to Present, Marginal or Absent tag expression respectively c. Tissue refers to one of the twelve human tissues 4) AffyMetrix Tag and Number refer to the AffyMetrix Tag ID and microarray replicate number, select these if you are interested in the details 5) Click Submit. Sample Satellog Output This query gives all the CAG repeat co-ordinates that are within coding sequences, along with the peptide sequence they encode, the HUGO name of the gene they are within and their EnsEMBL Gene ID (output truncated for example). In this example, only those repeats encoding at least five glutamines are output and within genes expressed in the Brain are shown.Some repeats are shown more than once because their gene maps to more than one AffyMetrix tag (tag names not shown).
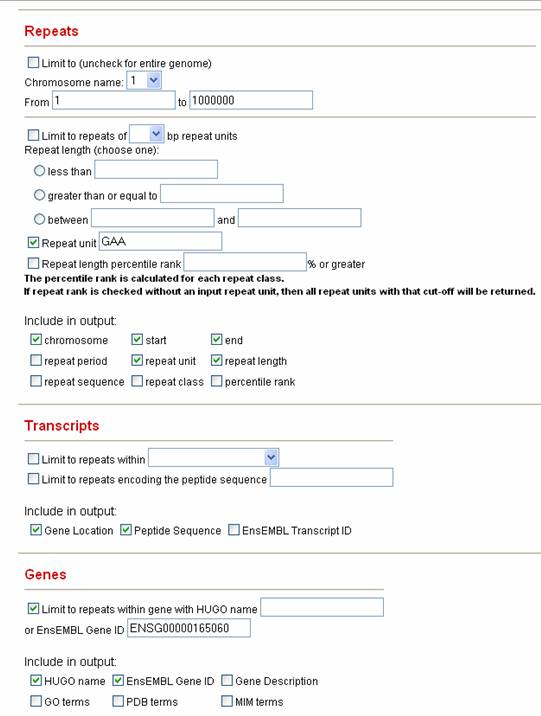
1.2.4 Show me all the repeats of type GAA in the Frataxin gene. GAA repeats in the Frataxin gene have been associated with Friedreichs Ataxia. Using Satellog, we can identify all of the GAA repeats in this gene and find the one associated with disease. Given any gene, Satellog can return either all the repeats, or certain repeats of a given size, repeat class, or within a specified genetic region.
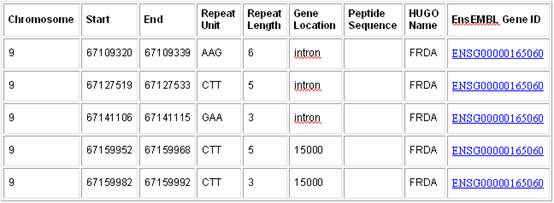
1) Uncheck the Limit to box because we are interested in the genome-wide distribution of GAA repeats. 2) Change Repeat Unit to GAA 3) Select the Repeat Output variables of interest 4) Under transcripts, check Gene Location and Peptide Sequence. 5) Also under transcripts, check Limit to repeats within gene with... and input the EnsEMBL Gene ID for Frataxin ( ENSG00000165060). It is always safer to use the EnsEMBL Gene ID because its stable whereas HUGO gene names can change over time. 6) Under Genes, select HUGO Name and EnsEMBL Gene ID. 7) Click Submit. Sample Satellog Output This query gives all the GAA repeat co-ordinates that are within the Frataxin gene, along with the gene location, peptide sequence they encode, HUGO name of the gene they are within and their EnsEMBL Gene ID.In this example, chr9:67109320-67109339 is the disease-associated repeat. Note: all disease associated repeats detected by our group in Satellog are available in the Downloads section.
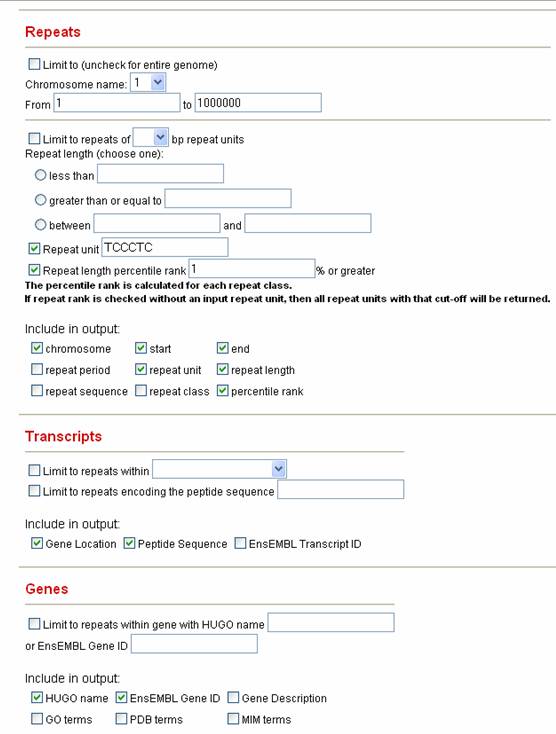
1.2.5 Show me the largest 1% of TCCCTC repeats in the genome. Researchers are usually interested in the largest repeats of a given repeat class because these are usually the substrates for subsequent expansion.However, when interested in a class there is no way to know what the largest repeat sizes are.For instance, TCCCTC repeats range from being repeated twice to 54 times. It is possible to eliminate guesswork and select the top X% largest repeats of any class easily with Satellog.
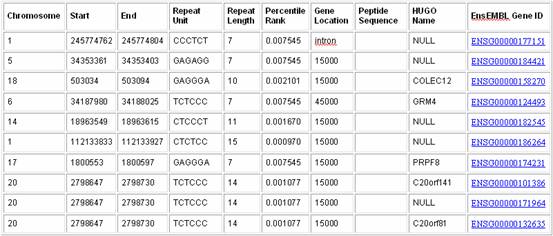
1) Uncheck the Limit to box because we are interested in the genome-wide distribution of TCCCTC repeats. 2) Change Repeat Unit to TCCCTC 3) Select the Repeat Output variables of interest and ensure to check off Repeat length percentile rank and input 1 and Percentile Rank for the output. 4) Under transcripts, check Gene Location and Peptide Sequence. 5) Under Genes, select HUGO Name and EnsEMBL Gene ID. 6) Click Submit. Sample Satellog Output This query gives all the TCCCTC repeat co-ordinates, along with their percentile rank, gene location, peptide sequence, HUGO name of the gene they are within and their EnsEMBL Gene ID. The percentile rank refers to the fraction of TCCCTC repeats that are as large as or larger than the length of each output repeat. For example, the first repeat has a repeat length that is as large as or larger than 0.7545% of all TCCCTC repeats in the human genome.
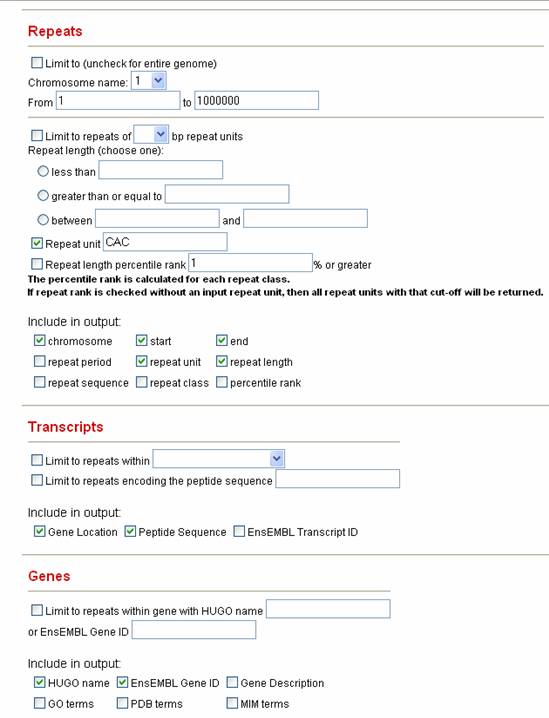
1.2.6 Show me all the polymorphic CAC repeats (as detected in UniGene clusters). Researchers are usually interested in repeats that already have evidence of length polymorphism and are near or within candidate genes.With Satellog, it is possible to identify candidate polymorphic sites in the human genome that are not documented elsewhere.Every transcribed repeat in Satellog has been analyzed within UniGene clusters to see if there is any evidence of repeat polymorphism.It is possible to extract just those repeats with possible polymorphism from any repeat class.Let us hypothesize that CAC repeats are an important new repeat class implicated in disease etiology and that we are interested in any potential polymorphic sites.
1) Uncheck the Limit to box because we are interested in the genome-wide distribution of CAC repeats. 2) Change Repeat Unit to CAC 3) Under transcripts, check Gene Location and Peptide Sequence. 4) Under Genes, select HUGO Name and EnsEMBL Gene ID.
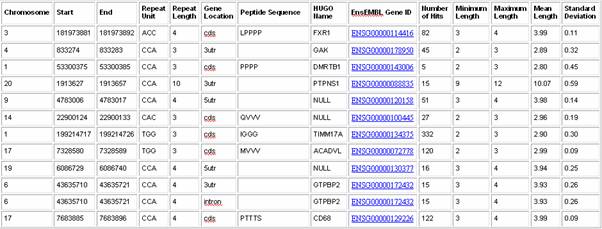
5) Under Polymorphism within UniGene clusters, check Limit to ....This will limit the output to repeats with one or more repeat length polymorphism. 6) Include the following summary statistics in the output: a. Number of Hits refers to the total number of times the repeat has been detected in UniGene sequences b. Minimum Length refers to the minimum repeat length detected in any of the hits. c. Maximum Length refers to the maximum repeat length detected in any of the hits. d. Mean Length - refers to the mean length of all detected hits e. Standard Deviation describes the standard deviation of all hits detected. Repeats with a larger standard deviation have more extreme polymorphism f. Note: UniGene cluster, UniGene sequence and Length within UniGene Sequence provide the information about each UniGene hit and are not included in this output. For practical purposes, these are only useful if one is interested in double-checking the hits reported by Satellog. 7) Click Submit. Sample Satellog Output This query gives all the CAC repeat co-ordinates, along with their gene location, peptide sequence, HUGO name of the gene they are within and their EnsEMBL Gene ID.Summary statistics about their UniGene hits are also provided to give a complete picture of their polymorphism.For example, chr17: 7950744-7950782 has a standard deviation of 2.12 but only has 2 hits.
| ||||||||||||||||||||||||||||||||||